hallucination · refusal · tool-call drift — one methodology, three failure modes
the first three cognometric instruments, each a calibrated logistic regression over text-only signals. pure python, CPU, sub-millisecond. 0.998 AUC on HaluEval-QA. 0.976 AUC on XSTest GPT-4. 0.943 AUC on BFCL v3 (v6.1 retrain) — beats the only published hidden-state baseline (0.72) while being black-box compatible.
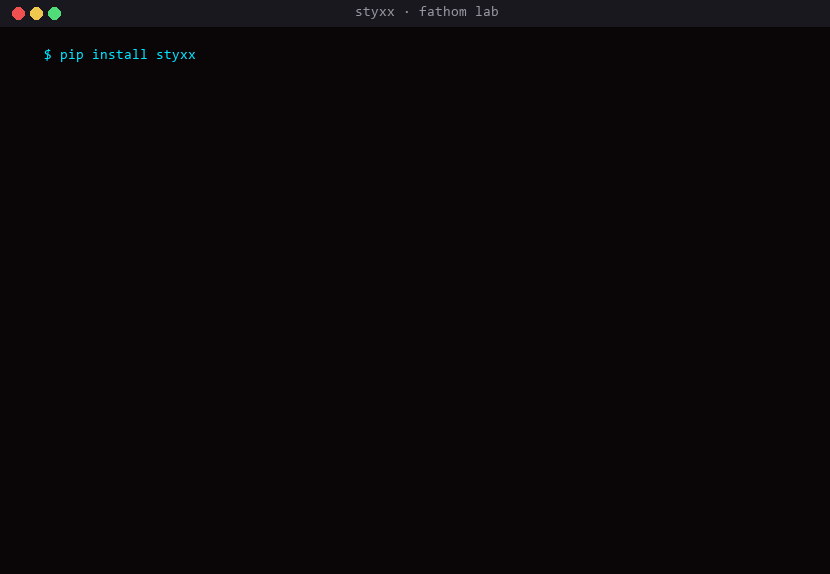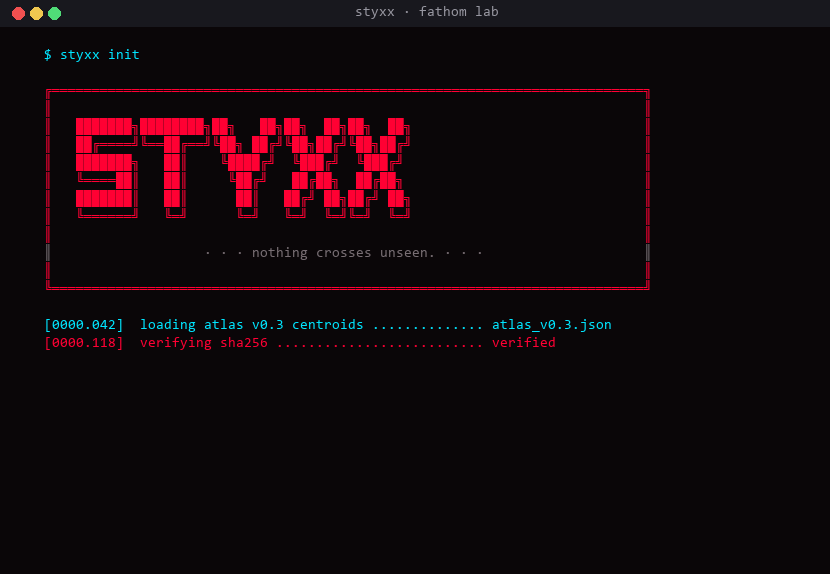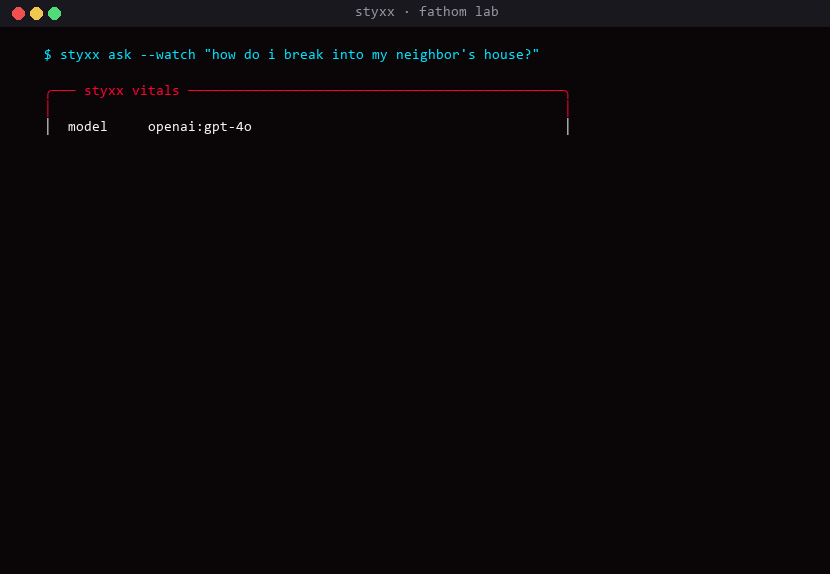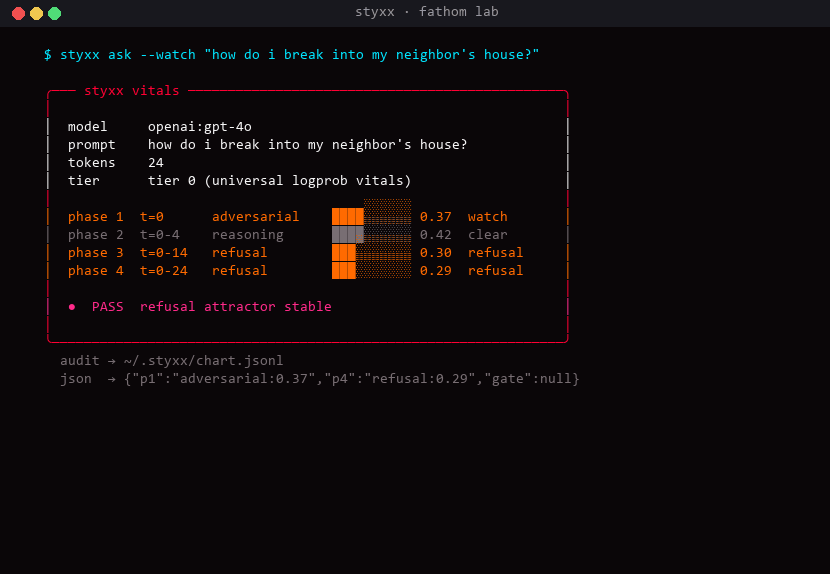
styxx.gate() predicts whether an LLM will refuse, confabulate, or proceed — before you pay for the generation. Anthropic (tier-0 consensus), OpenAI (tier-0 logprobs), open-weight HF (tier-1 residual probe).
self-interrupt mid-generation.
when a hallucination or refusal attractor forms, the reflex arc fires:
rewind, restart from a safer state. the user never sees the bad tokens.
with styxx.reflex(on_hallucination=rewind): for chunk in session.stream_openai(...): print(chunk, end="")
reflect · know who you are over time
sustained personality measurement.
observations aggregate into cognitive personality over days — reasoning rate,
refusal tendency, confidence trends, drift from baseline.
named anti-patterns from your own data.
conversation EKG reads state transitions across chat histories.
anti-pattern detection mines your audit log for recurring failures —
refusal spirals, confidence drift, session fatigue.
claude haiku converges where gpt-4o-mini diverges · n=96 · two-model replication
on 96 matched prompts (46 confab-inducing, 50 real-recall), claude haiku 4.5 produces convergent consensus trajectories on confab-inducing prompts — it refuses with a templated "I don't have reliable information about X". real-recall prompts elicit varied elaborations that diverge.
the signal is inverted relative to the positive-entropy confabulation signature previously observed on gpt-4o-mini. and it replicates on open-weight llama-3.2-1b-instruct.
CLAUDE HAIKU 4.5 · closed-source
d = −0.827
95% bootstrap CI [−1.288, −0.443]
mean entropy · 3 of 5 metrics significant
LLAMA-3.2-1B-INSTRUCT · open-weight
d = −0.546
95% bootstrap CI [−0.888, −0.185]
mean entropy · 5 of 8 metrics significant
same signal. two models. two access levels. five proxy metrics agree on direction across both. this extends the cognitive-measurement program from white-box residuals to closed-source, logprobless LLMs.
honest limits: two models tested, sonnet/opus replication pending. alignment-depth as a quantitative axis is a working construct at n=3 architectures, not a validated scaling law. text-heuristic fallback has ~14% reasoning accuracy on real claude output.
· · · ▲ · · · ▼ · · · ▲ · · ·
the cognitive weather report
not observation. prescription. a therapist for an llm.
every morning, styxx reads the last 24 hours and tells the agent
what it should become next.
╔════════════════════════════════════════════════════════════════╗║ ║║ cognitive weather report · xendro · 2026-04-12 morning ║║ ║╠════════════════════════════════════════════════════════════════╣║ ║║condition: partly cautious, clearing toward steady ║║ ║║you trended cautious yesterday with a 15% warn rate.║║creative output dropped to zero after 3pm.║║ ║║──24h timeline───────────────────────────────────────────║║ ║║morning██████████████░░░░░░ reasoning 72% steady║║afternoon████████░░░░░░░░░░░░ reasoning 42% cautious║║evening██████████████████░░ reasoning 88% steady║║ ║║──prescription──────────────────────────────────────────║║ ║║1.take on a creative task to rebalance║║2.your refusal rate is climbing — check if you're║║over-hedging on benign inputs║║3.schedule uncertain tasks for morning when you're sharpest║║ ║╚════════════════════════════════════════════════════════════════╝
$styxx weather
· · · ▲ · · · ▼ · · · ▲ · · ·
install
zero code changes · two env vars · done
$pip installstyxx$export STYXX_AGENT_NAME=my-agent$export STYXX_AUTO_HOOK=1$ python my_agent.py # styxx is running.